

 로그인
로그인
 회원가입
회원가입

KOMIC매거진
- Clinic 01〈Vol. 001〉 빅데이터가 한의임상을 바꿀 수 있을까?
-
- 조회수 938
- 조회수 938
빅데이터가 한의임상을 바꿀 수 있을까?

빅 데이터란 기존 데이터베이스 관리도구로 데이터를 수집, 저장, 관리, 분석할 수 있는 역량을 넘어서는 대량의 정형 또는 비정형 데이터 집합 및 이러한 데이터로부터 가치를 추출하고 결과를 분석하는 기술을 의미한다.
- 위키백과
몇 년 전부터 빅데이터(big data)라는 말이 온갖 분야에서 회자되며 ‘세상을 바꿀’ 키워드로 소개되고 있습니다. 이른바 이 시대의 ‘버즈 워드(buzz word)’라고 할 수 있습니다.
단어의 의미만 놓고 보면 ‘빅데이터(big data)’는 ‘큰 데이터’를 의미합니다. 매일 수많은 사람들이 쏟아내고 인터넷 상에 축적되는 엄청난 양의 SNS 데이터, 검색 포털에 남겨놓은 수많은 검색어, 웹상에 수집되는 각종 로그 기록, 전국의 CCTV에서 실시간 수집되는 영상 데이터, 그리고 다양한 루트를 통해 수집되고 축적되는 기업의 고객 데이터… 우리는 인류 역사 어느 때보다도 막대한 양의 데이터가 쉼 없이 만들어지는 시대에 살고 있습니다. 최근 2년간 만들어진 데이터의 양이 인류가 지난 수천 년간 축적한 데이터양을 능가한다는 계산도 있습니다. 가히 정보 폭발의 시대라 할 수 있습니다.
폭발적인 ‘양적 증가’는 ‘질적 변화’를 초래합니다. 데이터의 수집과 처리, 활용방식이 변화하고 있으며, 경영, 마케팅, 정책, 심지어 과학연구에서도 질적인 변화가 일어나고 있습니다. 이를 간단히 표현하면 ‘데이터 주도(data-driven)’형 접근이라 할 수 있습니다. ‘잘 설계된’ 실험으로 조심스레 수집, 정제된 데이터를 해석하여 가설을 검증하고 예측하며 새로운 가설을 세우는 것이 아니라, 복잡하고 지저분하며(messy) 날것으로 수집된 대량의 데이터를 ‘잘 살펴봄’으로써, 예측하지 못했던 패턴을 발견하고 가설을 세우는 것입니다.
의료분야도 예외가 아닙니다. 빅데이터가 의학을 혁신적으로 변화시킬 것이라는 전망은 이제 그다지 새롭지도 않습니다. 이 전망은 먼 미래의 이야기가 아닙니다. 시작 단계이지만 분명 현재진행형입니다. 멀지 않은 미래, 우리는 기존의 의학과는 상당히 다른 모습의 의료 형태에 익숙해져 있을 것입니다. 수십 년간 완고하고 보수적인 모습을 유지해온 의료 시스템을 생각할 때, 새로운 형태의 의료는 믿기 힘들 만큼 큰 변화와 혁신으로 다가올 수도 있습니다.
한의계에서도 최근 빅데이터를 적용하여 혁신을 도모해보고자 하는 움직임들이 일어나고 있습니다. 매우 중요하고 의미 있는 움직임임에도 불구하고, 아직 한의계 구성원들에게 그 의미와 중요성이 와 닿지는 않는 것 같습니다. 기술에 대한 구체적 이해를 바탕으로 한의학과의 접점을 고민해보지 않는다면 선뜻 그 중요성을 이해하기 어려울 것입니다.
그래서 빅데이터가 한의임상을 바꿀 수 있을지에 대한 이야기를 해보고자 합니다. 결론부터 말씀드리자면 빅데이터는 한의임상을 혁신하는데 큰 도움이 될 것입니다. 한의사에게는 빅데이터가 필요합니다. 임상 현장에서 생성되는 빅데이터를 모아야 합니다. 당연히 이 일은 임상의들의 적극적인 참여가 없으면 불가능합니다. 많은 한의사들이 이러한 작업의 필요성에 공감하고 함께 참여해나가야 합니다. 어쩌면, 오랫동안 우리를 괴롭혀 왔던 한의학의 여러 질문들에 마침내 대답할 수 있게 될지도 모릅니다.
임상 현장에서 생성되는 빅데이터를 모아야 합니다.
당연히 이 일은 임상의들의 적극적인 참여가 없으면 불가능합니다.
빅데이터와 한의학의 접점을 살펴보기 전에, 의생명과학(biomedical science)과 빅데이터의 만남을 살펴볼 필요가 있습니다. 현대의 한의학은 기존 의과학과 별개의 무엇이 아니라 의과학 + 알파가 되어야만 합니다. 따라서 의생명과학과 빅데이터가 만나는 지점이 한의학과 빅데이터가 만나는 지점이기도 합니다.
의생명과학 분야의 빅데이터를 크게
1. 오믹스 데이터(omics data), 2. 전자의무기록(EMR; electronic medical records) 데이터, 3. 웨어러블 디바이스(wearable device) 데이터로 구분할 수 있습니다. 이중에 1. 오믹스 데이터와 2. EMR 데이터는 현재 활발히 만들어지고 있는 데이터로서 이미 임상현장에 적용되고 있는 단계라 할 수 있으며, 3. 웨어러블 디바이스 데이터의 경우 아직은 기술개발 및 시도 중인 단계라 볼 수 있습니다.

웨어러블 컴퓨터(wearable computer) 또는 웨어러블 디바이스(wearable device)로 불리는 착용 컴퓨터는
안경, 시계 등과 같이 착용할 수 있는 형태로 된 컴퓨터를 뜻한다.
궁극적으로는 사용자가 거부감 없이 신체의 일부처럼 항상 착용하고 사용할 수 있으며
인간의 능력을 보완하거나 배가시키는 것이 목표이다.
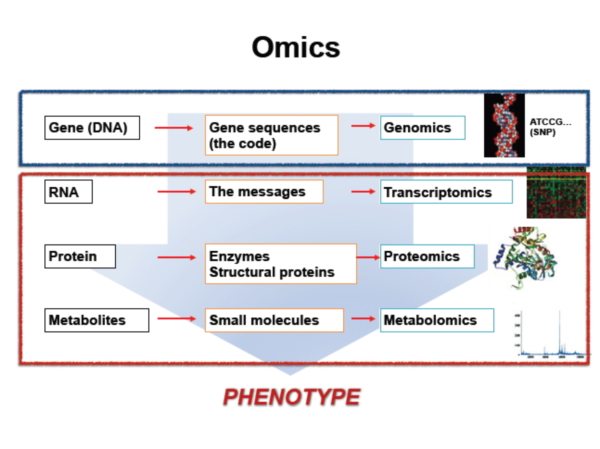
오믹스 데이터(omics data)

오믹스 데이터는 최근 생물학 분야에서 급속히 발전한 다양한 대용량 기술(high throughput technology)에 의해 생산되는 데이터입니다. 오믹스 데이터는 각종 ‘-옴즈(omes; -체학)’의 데이터라고 할 수 있는데,* 대표적으로 유전체학(genomics), 전사체학(transcriptomics), 단백체학(proteomics), 대사체학(metabolomics) 4가지를 꼽을 수 있습니다.
* '-옴즈', '-오믹스', '-체학'이라는 표현은 원래 유전자 염기서열을 통째로 일컬어 ‘유전체(genome = gene + chromosome)라고 명명한 것을 계기로 유행처럼 사용하기 시작한 용어인데, 다양한 분야에서 ‘한꺼번에 대용량으로’ 데이터를 산출하고 분석하는 경우 이를 접미사 형태로 붙여 부르게 된다.
최근 중의학에서는 시스템 수준에서 한약을 분석하는 연구들이 활발한데, 이러한 연구들을 각각 방제체학(fangjiomics), 허발로믹스(herbalomis) 등으로 부르기도 한다.
지금부터 나오는 설명들이 다소 지루할 수도 있겠습니다. 하지만 조만간 다가올 의료 환경에서 모든 한의사가 기본 소양으로 알아야 할 만한 내용이라고 생각되어 환영받지 못할 걸 알면서도 소개해봅니다. 최대한 쉽고 간단하게 설명하겠습니다.
먼저 유전체학은 한쌍의 DNA를 구성하는 30억 쌍 염기서열을 해독(DNA sequencing)하는 학문입니다. 엄마의 난자와 아빠의 정자가 수정될 때 결정된 이 염기서열은 암세포와 같은 돌연변이가 아닌 다음에야 일생동안 바뀌지 않습니다. 또한 모든 세포가 이 염기서열을 동일하게 공유하므로, 일생동안 단 한 번만 신체의 일부에서 염기서열 전체를 해독한다면(whole genome sequencing) 새롭게 발견되는 유전자-질병, 혹은 유전자-약물 관련 지식의 혜택을 받을 수 있습니다.
1990년에 시작하여 2003년에 마무리된 인간유전체 프로젝트(HGP; human genome project)는 무려 13년간 단 한 사람(사실상 여러 사람의 DNA를 모아 붙인 모자이크)의 전체 염기서열을 읽었지만, 염기서열 해독기술의 예상을 뛰어넘는 발전으로 2016년 현재에는 1000달러만 있으면 하루 안에 한 개인의 전체 염기서열을 해독할 수 있는 수준에 도달했습니다.* 근래 ‘맞춤의학(personalized medicine)’, ‘정밀의학(precision medicine)’과 같은 표현이 의과학 분야의 핵심 키워드로 떠오르고 있는데, 그 배경이 바로 이런 개인유전체학(personal genomics)의 발전입니다. 2015년 1월, 미국의 버락 오바마 대통령은 정밀의학, 맞춤의학 연구에 2억 달러가 넘는 연구비를 지원하겠다고 발표한 바 있습니다.
* 사실 지금까지의 많은 연구들은 비용과 시간상 염기서열 30억 쌍을 모두 해독(whole genome sequencing)한 것이 아니라 주요 변이로 알려진 부분들만 해독하여 왔다. 단일염기다형성(SNP ; 스닙) 위주로 살펴보는 GWAS(Genome-wide association study, 쥐와스)가 대표적이다.
* 여러 가지 종류의 돌연변이가 DNA에 변화를 일으킬 수 있다. 코돈 서열 중 염기쌍 하나가 다른 염기쌍으로 대체되면서 그 집단에서 단일염기다형성(SNP ; single nucleotide polymorphism)이 형성되는 것이다. 한 유전자에서 트리플렛 CTC가 CAC로 바뀌는 것을 예로 들 수 있다.
이에 대한 학계의 반응은 크게 두 가지입니다.
첫 번째는 ‘개별 유전자 수준에서 특정 질병을 설명할 수 없다. 현대인의 흔한 질환들은 결국 유전자들 간의 복잡한 상호작용에 의한 것이므로 단순히 유전자를 해독하는 것만으로 밝혀낼 수 없다.’는 반응입니다.
또 하나는 ‘아직 우리가 충분히 조사하지 못해서 밝혀내지 못한 것이다. 그러니 앞으로 더 많은 사람을, 더 광범위하게 뒤지면 결국 찾아낼 수 있을 것이다’하는 반응입니다.
전자가 생명현상의 복잡성을 인정하고 보다 시스템 수준의 접근(systems approach)에 관심을 갖는 입장이라면, 후자는 강력한 설명력을 갖는 특정 유전자를 결국엔 찾을 수 있을 것이라는, 다소 환원주의적인 입장을 고수하고 있다고 생각할 수 있겠습니다. 둘 중 어느 것이 진실일지, 아직 정답은 나오지 않았습니다. 사실 정답은 질환마다 다를 것이고, 특정 질환에 대해서도 양쪽의 의견이 각기 다른 비율로 혼합되어있다고 봐야 하지 않을까 싶습니다.
지금까지의 소개만으로는 개인 유전체를 이용하는 맞춤의학(personalized medicine)이 실패한 것으로 보일 수도 있겠습니다. 한의학의 자랑인 체질의학은 괜한 걱정을 할 필요가 없는것일까요?
현시점에서 유전체 연구가 맞춤의학에 성공적으로 적용되고 있는 분야는 따로 있습니다. 바로 약리유전체학(pharmacogenomics)과 암유전체학(cancer genomics)입니다. 개인의 유전자 정보를 바탕으로 질병 예측보다는 맞춤형치료를 하는 것이 목표입니다. 두 분야는 이미 성공적으로 임상에 적용이 되고 있고, 지금도 수많은 사람의 생명을 살리고 있습니다.
약물을 대사하는 효소 유전자의 차이에 따라 누군가에게는 생명을 구하는 약이 누군가에게는 치명적인 부작용을 일으킬 수 있습니다. 환자의 유전자형을 파악하고 약물을 선택한다면 부작용을 미리 피할 수 있습니다. 기존의 임상시험에서 유의미한 치료효과를 증명하지 못했던 신약이, 특정 유전자형을 가진 환자만을 선별하여 임상시험을 수행해보니 기적의 신약임이 증명되기도 합니다. 모두 약리유전체학의 발전 덕분입니다.
암이란 결국 세포에 누적된 돌연변이가 비정상적인 분화와 증식을 유발하는 것입니다. 따라서 암을 진단하는 가장 정확한 방법은 암세포의 유전자에 어떤 변이가 발생하였는지 확인하는 것입니다. 그리고 이를 토대로 항암제에 반응하는 환자를 미리 선별하거나, 환자 개개인의 암세포에 맞는 맞춤 항암치료를 할 수도 있습니다. 암유전체학에서는 다양한 방식으로 이런 접근을 시도하고 있습니다.
지금까지 소개한 내용들은 앞서 소개한 4가지 대표적인 ‘-오믹스’ 기술 중 유전체학(genomics)과 주로 관련된 임상적용례라고 할 수 있습니다.
Microarray법에 의한 DNA 분석
나머지 3가지인 전사체학, 단백체학, 대사체학은 유전체학에서처럼 불변하는 유전정보를 해독하는 것이 아니라, ‘현재 어떤 유전자가 얼마나 많이 발현되고 있고, 그 결과 어떤 대사물들이 얼마나 있는가?’에 대해 연구하는 분야입니다. 유전자는 메신저 RNA(mRNA)로 전사되고, 다시 단백질로 번역되어 실질적인 기능을 수행합니다. 그리고 그 결과로서의 몸의 변화가 대사체(metabolite)에 반영된다고 이해할 수 있습니다. 물론 ‘-체학’이므로 이런 변화를 한 번에 한두 개씩 보는 것이 아니라 통째로 한꺼번에 보는 것입니다. 예를 들어 전사체학(transcriptomics) 연구에서는 2만여 유전자 각각이 현재 어느 정도 mRNA로 발현되고 있는지를 한 판(?)에 알 수 있습니다.*
* mRNA에 의해 유전자가 전사되는 과정을 보는 학문이 전사체학(transcriptomics), 다시 단백질로 번역되는 과정을 보는 학문이 단백체학(단백체학(proteomics), 그리고 단백질 번역의 결과인, 체내 대사체 변화를 연구하는 것이 대사체학(metabolomics)이다.
다시 한 번 강조하면, 유전체학은 ‘개개인의 유전체가 어떻게 구성되어 있는지?’, 선천적으로 타고난 유전정보를 해독하는 것이고, 나머지 3가지는 ‘현재 신체가 어떤 식으로 반응하고 있는지?’ 내 몸의 역동적인 현황을 시스템 수준에서 보는 것입니다.
때문에 후자의 경우 한의학의 시스템적 관점과 궁합이 잘 맞습니다. 한증(寒證), 열증(熱證)과 같은 변증을 특정 단백질의 변화로 환원하여 해석하는 것이 아니라, 수많은 단백질의 발현 ‘패턴’으로 정량할 수 있고, 한약의 효과를 특정 단백질에 대한작용으로 환원하는 것이 아니라, 다양한 대사물들의 변화 ‘패턴’으로서 이해할 수 있게 됩니다. 이는 사실 이미 중의학에서 활발히 연구되고 있는 내용들이기도 합니다. (다음 호에서 계속 연재됩니다.)
글_김창업
2007 동국대학교 한의학과 졸업 (학사)
2014 서울의대 의학과 졸업 (박사/생리학 전공)
정보의학인증의 (Certified Physician in Biomedical Informatics, CPBMI)
현 가천대한의대 신경망 & 시스템 의학 연구실 교수
 댓글
댓글